
#67 - MegaETH: Building a Real-Time Blockchain
Putting Performance First


Stanford Blockchain Review
Volume 7, Article No. 7
✍🏻 Author: Sami — DevRel at MegaETH
⭐️ Technical Prerequisite: Intermediate
At MegaETH, performance isn’t an afterthought— it’s the bedrock of what we’re building. Our blockchain is designed from the ground up with the north stars of providing high throughput and more importantly, low latency, to enable apps that were previously impossible. In this article, we’ll explore our design philosophy, the approaches we’ve taken, the tradeoffs we embrace and the benchmarking to support our claims— all of which we wear proudly and unapologetically.
Understanding Latency
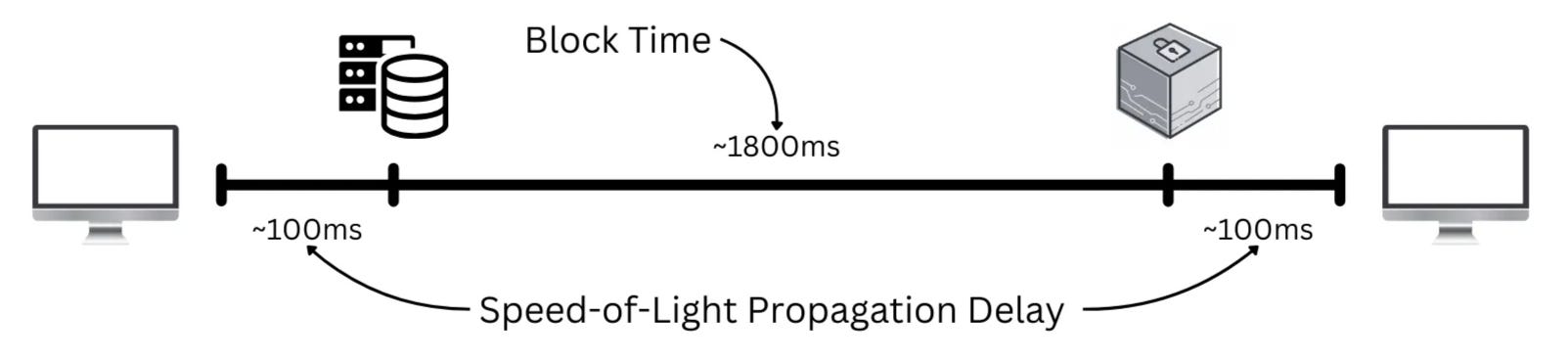
Let’s begin with an overview of the lifecycle of end-to-end latency. A given transaction will begin in your browser at home and needs to travel to the block producer. This first step, often referred to as the ‘speed-of-light propagation delay’, takes ~100ms for most city pairs. Short of colocating with the block producer—which may only be necessary for latency-critical applications such as on-chain CLOBS—there isn’t much that can physically be done to optimize this stage.
Once a transaction arrives at a block producer, we enter the domain of block time, where the transaction will likely wait in a memory pool before it is batched, sequenced, and executed. On Ethereum mainnet, this process takes around 12s, whereas performance focused blockchains bring it down to 1-2s.
Lastly, a receipt needs to travel back to the user, adding another ~100ms. Given that the propagation delays are a physical limit, and relatively insignificant, this article will focus on the part that can be optimized— block times.
Sequencing & DA
Above, I mentioned that a transaction must wait in a memory pool before being sequenced— that’s not strictly true and is a byproduct of batched sequencing. Conventional sequencing is done via a consensus algorithm, which, no matter how optimized, requires sending messages at least twice around the world (here we’re not allowed to relinquish responsibility for speed of light delays).
By replacing the consensus algorithm with centralized block production, we eliminate the need for coordination between multiple parties to produce blocks. This allows the active server to process transactions as a continuous stream, rather than having them queue to be batched, minimizing the idle time between blocks.

Here we introduce a key tradeoff—centralized block production. Simply removing consensus and expecting a chain to remain secure is absurd, unless you build it on top of a properly decentralized Layer 1. This architecture was actually proposed by Vitalik Buterin in a 2021 blogpost titled Endgame (https://vitalik.eth.limo/general/2021/12/06/endgame.html), where he concludes that all solutions to scale a blockchain inevitably lead to centralized block production.
But this illustrates something important that sets us apart: we don’t believe in reinventing the wheel, nor are we so arrogant as to think we can do everything best. Instead, we defer security to proven decentralized systems like Ethereum mainnet and EigenDA, allowing us to focus on performance.
Measure, Then Build
The next thing that sets us apart from other blockchains is the initial approach we took to designing our execution layer. Rather than making assumptions or guessing where improvements can be made, we decided to really understand the existing state of the art first. Unfortunately, finding up-to-date performance data proved to be difficult, which explains why the limitations of current systems are often poorly understood by most outside of their core engineering teams.
To address this, we took a methodical approach to experimentation (i.e. started from the ground up (i.e. i.e. decided to measure, then build)). This level of control and granularity allowed us to isolate and analyze specific bottlenecks.
— skip if not interested —
Test configuration:
CPU: Intel Xeon w5-2465X (16 core @ 3.1GHz)
RAM: Samsung 512G DDR5-4800
Disk: Intel SSD D7-P5510 7.68 TB (NVMe PCIe 4.0)
We started by using the Linux cgroup command to simulate machines with varying memory sizes. This allowed us to test cases such as limited memory and high-load. Then, we performed both historical sync and live sync experiments under various memory scenarios to attain a clear understanding of the limiting factors of execution clients, and how they evolve with different modes.
— come back! —
Important to know:
Historical Sync refers to syncing past blocks on a blockchain, without the need for real-time updates of state changes.
Live Sync is the process of syncing the blockchain while it is actively being updated, requiring continuous state updates and writing to the database after each block.
EVM Overhead
To isolate execution layer performance without database I/O distorting results, we ran a historical sync using 512GB memory, persisting changes every 500k blocks.

Looking at the transactions per second (TPS) of the first 18 million Ethereum mainnet blocks, we see that TPS averages at ~14,000 in the last million blocks. The TPS volatility preceding this can be attributed to transactions being less complex closer to genesis.
Now, is 14k TPS slow? Of course not. But is it fast enough for the World Computer? Unfortunately not. (Also, consider that this is not true TPS— it’s artificially high as disk I/O overhead is omitted).
To understand this constraint, we analyzed the time breakdown of a common smart contract when it is interpreted by the EVM. We then compared this to the same smart contract, but with its bytecode precompiled to native instructions before execution.
This highlighted a significant bottleneck in the EVM’s real-time translation of bytecode into CPU instructions, which occurs because smart contracts are compiled into bytecode and interpreted during execution. To alleviate this, we implemented Just-In-Time (JIT) compilation, which automatically translates the EVM bytecode into native machine code before execution. Testing against the most recent historic transactions from the ETH mainnet (as of January 2025) has resulted in substantial performance boosts for both average and compute-intensive applications.
State Update Overhead
In Figure 3 we found that the historical sync of the last million blocks achieved 14,000 TPS. When we transition this to live sync—which requires the update of the state root after each block—the average TPS for the same million blocks drops down to around 1000 TPS.

The 14x slowdown between historical sync and live sync can be attributed to two primary factors:
Merkleization Cost: Updating the state root through merkleization causes a 9.3x slowdown, even when the entire Merkle Patricia Trie (MPT) fits in memory. This is due to the need for extensive tree traversals to locate and modify nodes, and the fact that numerous nodes must be read before they can be modified.
State Writing: Writing the state changes to the database after each block incurs an additional 1.5x slowdown.
To minimize the number of database I/Os required during state updates, we replaced the traditional MPT with a newly designed state trie which significantly reduces disk I/O when updating the state. Additionally, due to the write-intensive nature of the application, we opted for a database optimized for writes.

Further analysis presented a fundamental problem with state access during the execution layer: over 80% of the time is spent on database I/O, with less than 20% on actual transaction execution. By moving the entire state into memory—effectively caching all state data—we were able to minimize disk access to just ~10% of the block assembly time.
A Real-Time Blockchain
Today, through the optimizations outlined above (along with many others), we’re able to reach 10ms block times, even under extreme loads (think 100k TPS). This level of performance empowers developers to build the apps that, they were previously told, are impossible on-chain.
A real-time blockchain will only be realized if we don’t apologize for putting performance first.
Author
Sami Muduroglu leads Developer Relations at MegaETH, overseeing developer onboarding and optimizing the developer experience. He has a keen interest in applied cryptography and high-performance systems. He is currently on leave from Brown University, where he studies Applied Mathematics and Computer Science. He has previously conducted research on how cloud contamination biases satellite observations of Arctic sea ice and worked in industry designing aerial radar-based landmine detection systems.
Huge thanks to Yilong Li for spearheading the research and Lei Yang for guidance and countless contributions.
Fascinating breakdown on the tradeoffs between decentralization and performance! The decision to embrace centralized block production on top of decentralized L1s feels pragmatic kind of like building high speed rails on a rock solid foundation rather than trying to redesign the entire transport system. How do you see developer UX evolving with these performance gains? Would love to hear your thoughts on what kinds of apps this unlocks.
Although most of the concepts regarding the data collection, measurement and improvements, flew over my head, I really did enjoy reading your research.